What should play the role of language for vision-language-action models?
In language models
Language is shareable: a reasoning trace is good when a different model can read it and recover the answer.
For robots
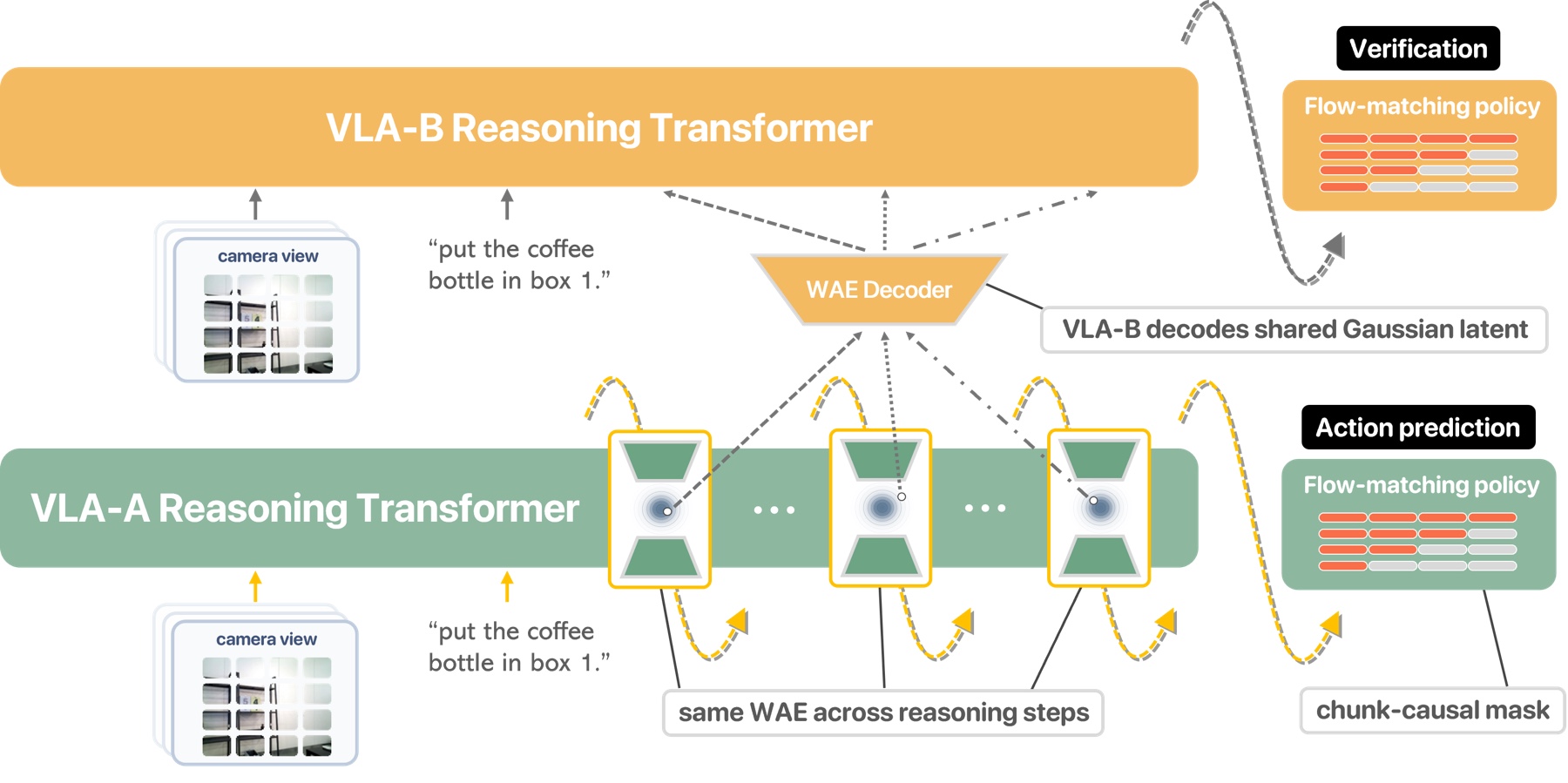
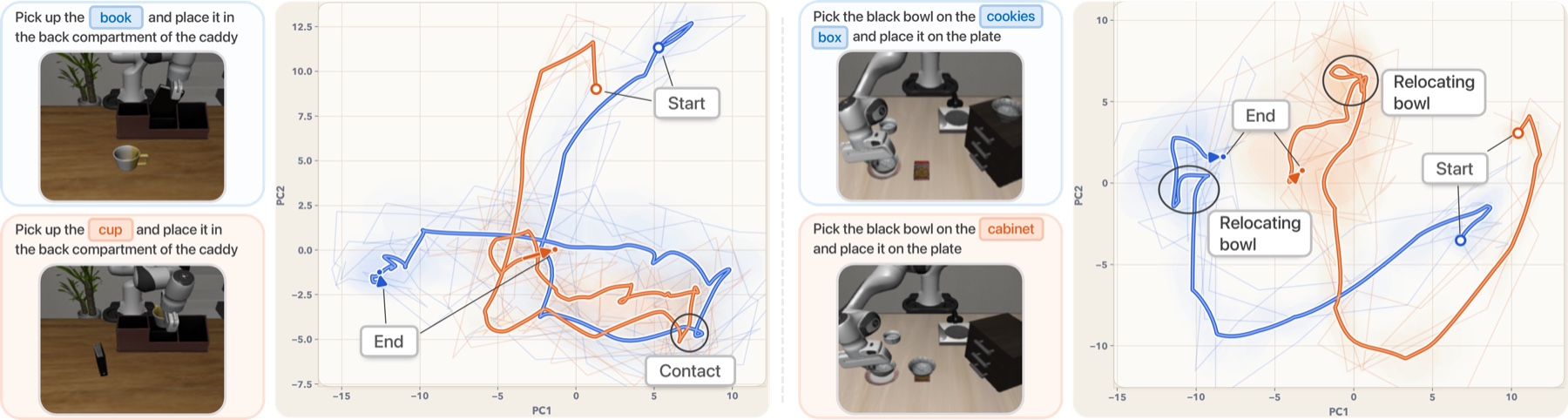
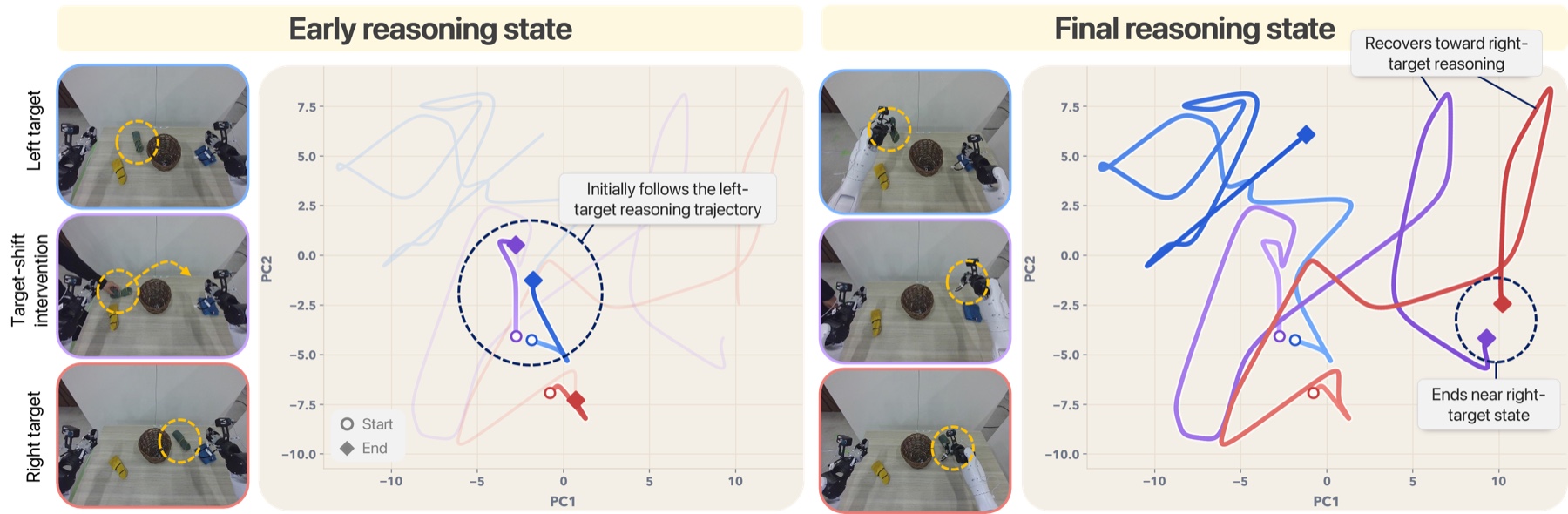
But a subtask like “put the bottle in box 1” spans many action chunks — too coarse to say what to do right now. So what plays its role? A shared latent, at the granularity of control, another policy can decode and verify through action prediction.
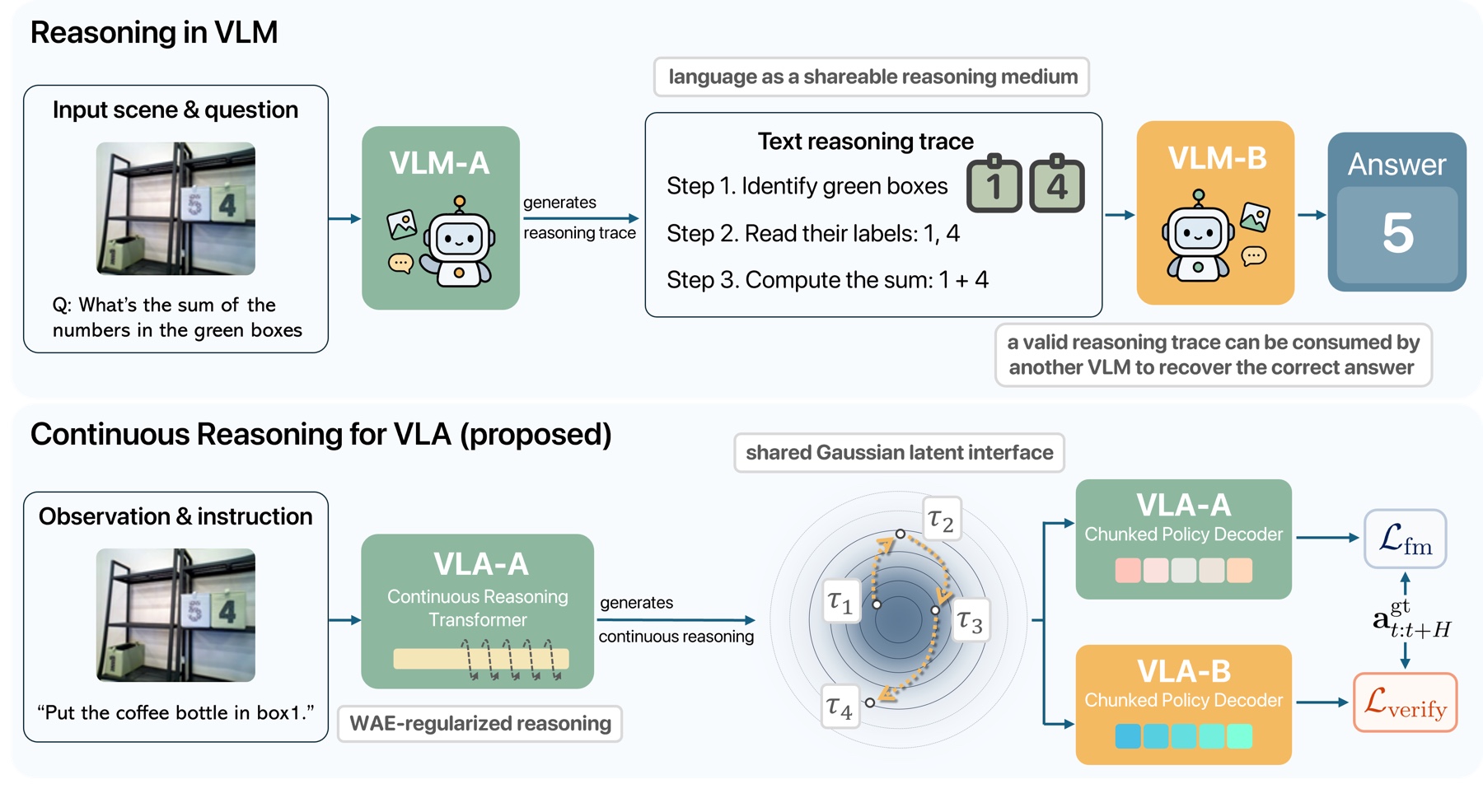
Top: in a VLM, another model can consume the trace to recover the answer. Bottom: Continuous Reasoning gives VLA the same property — a shared Gaussian latent a second policy must consume to predict the actions.